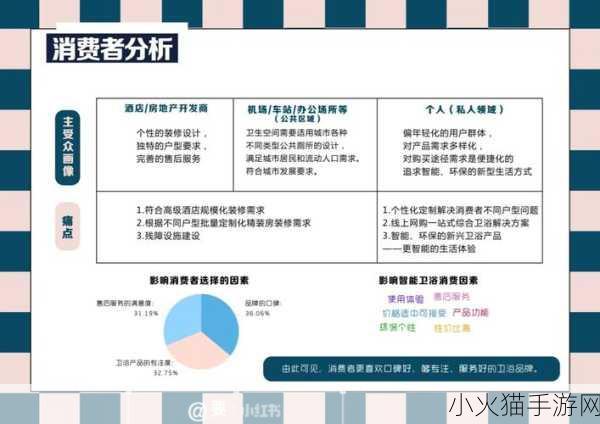
了解网站结构
在提取一个网站的数据之前,首先要熟悉其HTML结构。这包括识别出标题、段落和其他重要信息的位置。使用开发者工具可以轻松查看元素及其属性,帮助确定所需数据。
选择合适的编程语言
Python是一种流行的选择,它有许多强大的库,如BeautifulSoup和Scrapy,可以用于网页爬虫。在JavaScript中,也可以利用Node.js与Cheerio库来实现类似功能。根据具体要求选择最合适的技术栈,将显著提高效率。

发送请求并解析响应
能够模拟浏览器行为非常重要,这样才能获得动态加载的数据。例如,使用requests库(Python)或axios(JavaScript)发起HTTP请求。当成功接收到页面后,需要将返回的数据解析为易于处理的格式,例如JSON,以便进一步分析。
提取关键信息
soup.select('selector')等方法可高效定位目标数据,通过CSS选择器快速找到特定标签内的信息。例如,如果想提取所有产品名称,只需简单地调整选择器即可。此外,还应考虑到不同类型的网站可能会有不同形式的数据存储方式,因此灵活性至关重要。
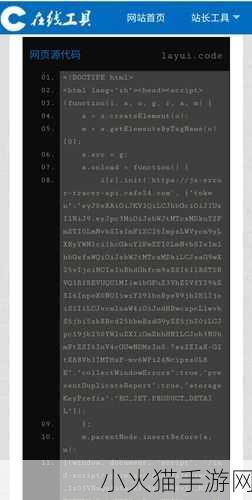
清洗与整理数据
Django ORM或Pandas这类工具能够有效提升数据处理能力。有时拿到的数据可能包含冗余信息或者缺失值,所以在写入数据库前一定要进行必要的清理工作,比如去除重复项、填充空值,以及统一格式等步骤,确保最终结果更具实用价值。
保存和展示内容
{@html} 函数使得呈现变得方便,同时也能保证安全性。如果希望让用户直接访问某个链接,可以采用锚点显示,让整个过程无缝连接。同时,可通过API将这些信息集成进应用,使得更新频率更高,更加贴近实时需求。”}
热点话题推荐:
- #Web Scraping技巧分享
- #未来科技发展趋势
- #程序员必备技能